Reconnaissance du locuteur : Etat de l’art
I- Le signal de parole
D’après Fourier, un signal est la somme des cosinus et des sinus. En effet, tout en décomposant un signal periodique, les sinus et les cosinus qui le composent vont signaler une fréquence précise, caractéristique d’un son.
Ceci montre qu’il y a de nombreuses fréquences différentes caractérisant le son de divers objets. À titre d’exemple, la fréquence d’échantillonnages : large bande 16000 valeurs par seconde (permet de garder une bonne qualité, quelques centaines de hertz à 8 kHz), le téléphone (bande étroite) 8000 valeurs par seconde etc.
Nota bene: un signal d’une seule seconde correspond à 1600 valeurs.
II- Le spectrogramme et la paramétrisation acoustique
- Le spectrogramme:
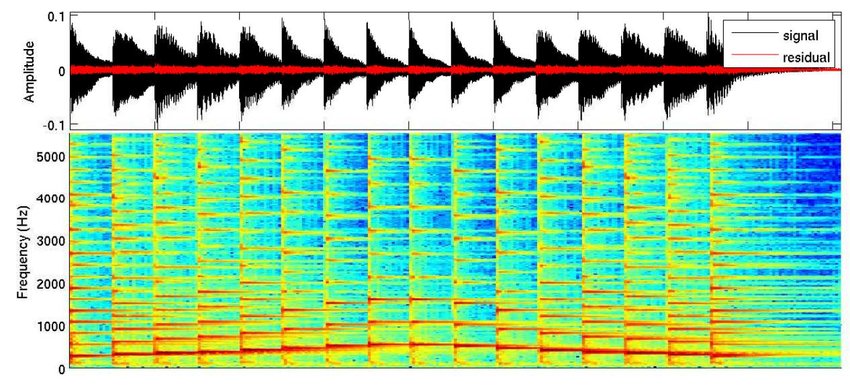
Le spectrogramme est une représentation qui montre la variation du signal en fonction de temps : ce qui se passe c’est quelque chose de reconnaissable qui correspond à une réalité statistique.
La représentation est divisée en plusieurs parties, normalement au bout de chaque signal ( 10 ms) et les amplitudes de fréquences -qui permettent la caractérisation de son (ils se diffèrent en chaque point) -qui le composent seront analysées .
2. La paramétrisation acoustique:
Toutes les 10 ms on extrait le spectre du spectrogramme , assez court (pas de coïncidence entre deux secondes) mais assez long pour qu’il y ai de l’information.
Une transformée de Fourrier (passage de temps vers les fréquences) aura lieu avant l’utilisation d’une échelle de barque.
Actuellement, un système end-to-end est adopté : Il utilise directement le signal de parole.
III- La reconnaissance du locuteur
Dans le but d’identifier l’identité d’un locuteur, une signature de base est utilisée. Par la suite, il y aura une comparaison avec un autre locuteur, selon les deux signatures, et une décision est prise (rejeter ou accepter, selon une distance de similarité, supérieur ou inférieur à un seuil).
Aperçu historique: Jusqu’aux années 2000, il y avait des systèmes statistiques insuffisant. Il y avait uniquement une approche avec un vecteur de taille variable. L’idée révolutionnaire était de transformer le signal de vecteur en taille variable en un vecteur de taille fixe. Ainsi, dans le but d’identifier le locuteur, un calcul de la distance séparant les deux vecteurs.
Depuis 2010, les réseaux de neurones prennent les vecteurs et les mettent dans une multitude de couche (convolutions1 munie d’un résiduelle permettant d’augmenter le nombre de paramètre tout en apprenant) ; il arrive à une couche de vecteur fixe représentant le locuteur. Il y a un passage par un classifieur là où il passe le vecteur fixe. Les lost functions maximises les bonnes probabilités et diminuent les mauvaises probabilités sur chaque session ainsi que sur la somme.
Apres ces étapes, un calcul de distance entre les deux vecteurs fixes permet de comparer les similarités: si les similarités sont grandes alors c’est le même locuteur, sinon ce n’est pas le même .
1- Convolution : on prend un filtre et on calcul chaque réseau et puis on se déplace, ainsi de suite. Maintenant, on prend de chaque case un résumé/ minimum… Chaque filtre passe à chercher une différente caractéristique. L’initialisation est aléatoire et chaque itération fait une tâche différente. Il y a un pulling à la fin.
Article écrit par Kinda CHAMMA, suite à une conférence avec un enseignant-chercheur du CERI, Driss MATROUF.