How to improve composite task oriented dialogue systems ?
When a user interacts with an agent (a robot or a program), the dialogue is mainly made up of one or several domains – like a restaurant, a hotel or an attraction – and one or several tasks – such as searching for a good restaurant which would fit our criteria or to book a hotel. This is a task-oriented dialogue.
A composite dialogue system has a composition of possible dialogue environments. So an agent which includes a composite dialogue system can talk about several domains and do several tasks.
Nowadays, composite task-oriented dialogue systems are efficient to satisfy different tasks about different domains (subjects) such as finding and booking a restaurant or a hotel. However these domains and tasks are defined during the learning step and adding a new domain or task is disabled after this step.
This is due to the representation of the information by the system, let us explain that in this article !
How does a task-oriented dialogue system work ?
Imagine you talk with an agent, the language used in the dialogue is the natural language. To talk with you, the agent needs to translate the natural language into a semantic representation (a language that it understands), it is the ontology. To do so, the dialogue system in the agent uses a Natural Language Understanding module (NLU) and it uses a Natural Language Generation module (NLG) to convert the semantic representation into a natural language.
During the translation, the dialogue system translates each term of the dialogue into dialogue acts, slots and values (Delexicalisation), and puts these on a vector (Vectorisation) to process the request. After the processing, the result is a vector and the DS needs again to transform it into dialogue acts, slots and values (Devectorisation then Lexicalisation).
For example, asking an agent to find the address of an american food restaurant in San Jose will look like that :
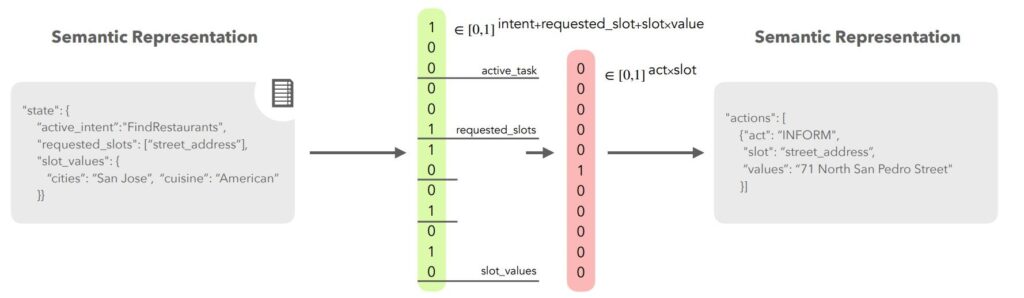
So the agent informs the user that there is an American food restaurant in San Jose at the 71th North San Pedro Street.
Improve the vector representation
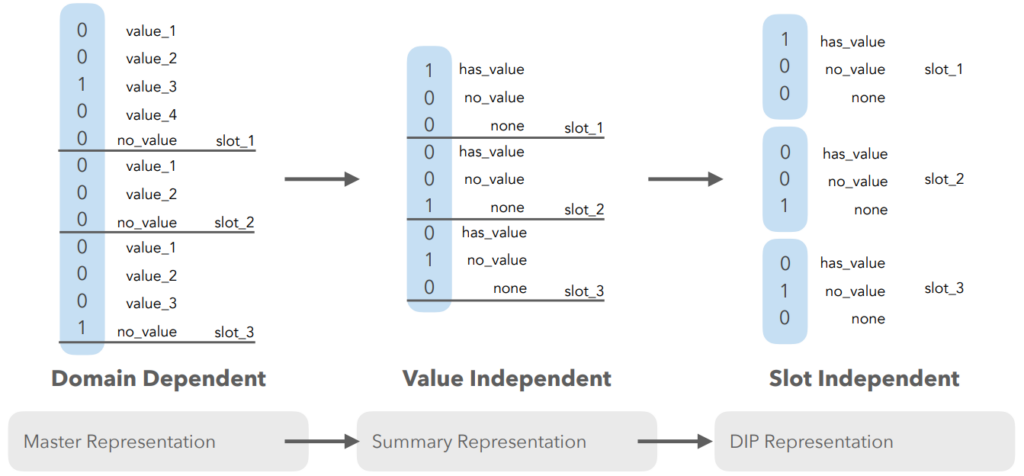
Currently, the representation of the information in a vector is a master representation, i.e. for one domain (e.g. Restaurant) there are many slots (e.g. food, city, etc) and in one slot there are many values (e.g. Italian, French, Chinese (for food)). This representation is defined during the learning step and it is domain dependent, i.e. adding a value or a slot after the learning phase is disabled.
To improve this representation there is the summary representation. There is no need to know the value but only if there is one or not. Adding a new value is now possible, but the issue of the domain dependency remains.
The representation can be definitely improved with the domain independent parameterization (DIP). It is the same representation as the summary one but the slots in the vector are separated into subvectors so it is now allowed to add values and slots in the representation.
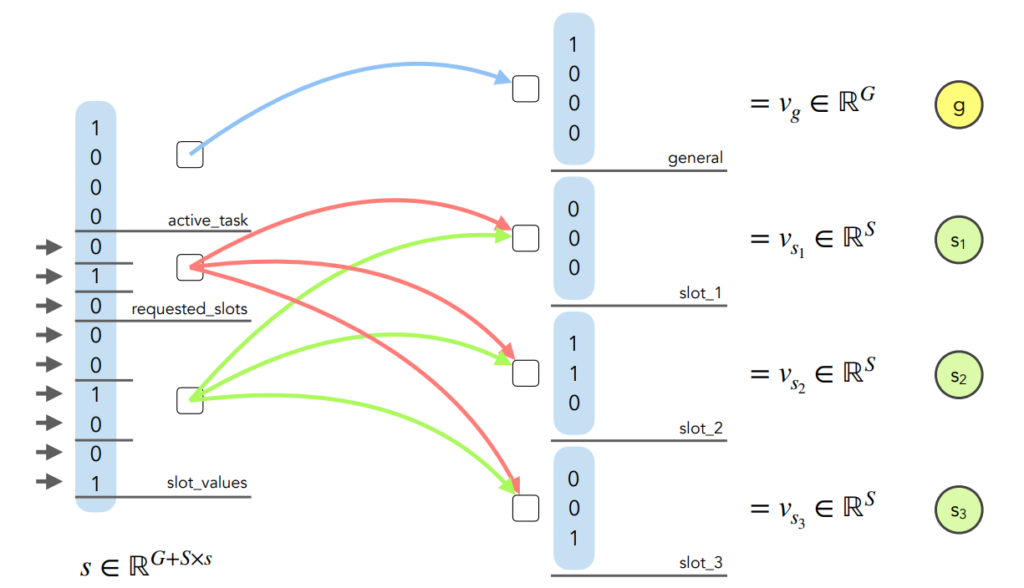
To make the connection with the previous representation : for a domain (e.g. restaurant) there is firstly a vector with the active task (e.g. finding), some requested slots (e.g. food, city and price range) and slots values. Then with the new representation there is one general subvector with some slot independent information – such as the active task, the number of slots, etc – and different slots which do not contain values, but just the information about the presence of the value, 1 if it is present, 0 elseway.
Improve the architecture of the model : architecture based on the DIP representation
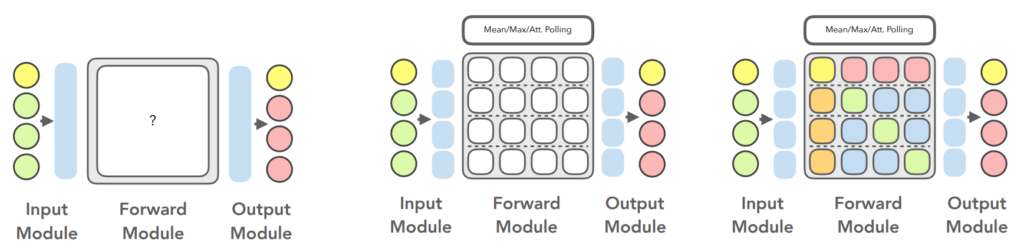
The left representation on the illustration is the classic representation of a neural network, i.e. the input module is a vector, the forward module is a layer (matrix) and the output module is also a vector. The issue with this representation is the same as before : it needs to relearn the model to add new values or slots.
That is why, based on the DIP representation, the layer could be composed of as many subblocks as slots in the input module. The information is symmetrical with respect to the diagonal. The aim of this representation is to enable the slot addition and the slot permutation invariance without having to relearn the model.